
Computational Correction of Eye Aberrations: A Physical Modeling Approach with Zernike Polynomials and Deep Learning
A computational correction strategy for eye aberrations, specifically targeting astigmatism, is proposed. This method computationally designs a transformed image that allows individuals with astigmatism to perceive the original scene with improved clarity. To achieve this, a convolutional neural network (CNN) is trained to minimize the error between a well-defined reference image and an image generated by convolving the transformed image with a simulated point spread function (PSF) representative of a person with astigmatism, modeled using the second-order Zernike polynomials Z22 and Z−22 • Additionally, upsampling techniques are applied to simulate zoom effects in the scene. Quantitative results demonstrate that bicubic scaling with a factor of 2 significantly enhances the perceived visual acuity of the person, increasing SSIM from 0.86 to 0.98 and PSNR from 25.8 dB to 37.7 dB under moderate distortion (severity 1.0). The model was trained on images from the KITTI dataset with simulated aberrations and evaluated on the DIV2K dataset, confirming its generalization to out-of-distribution data. These results highlight the effectiveness of integrating physics-based optical modeling with deep learning for ocular aberration correction.

High Dynamic Range Modulo Imaging for Robust Object Detection in Autonomous Driving
Object detection precision is crucial for ensuring the safety and efficacy of autonomous driving systems. The quality of acquired images directly influences the ability of autonomous driving systems to correctly recognize and respond to other vehicles, pedestrians, and obstacles in real-time. However, real environments present extreme variations in lighting, causing saturation problems and resulting in the loss of crucial details for detection. Traditionally, High Dynamic Range (HDR) images have been preferred for their ability to capture a broad spectrum of light intensities, but the need for multiple captures to construct HDR images is inefficient for real-time applications in autonomous vehicles. To address these issues, this work introduces the use of modulo sensors for robust object detection. The modulo sensor allows pixels to ‘reset/wrap’ upon reaching saturation level by acquiring an irradiance encoding image which can then be recovered using unwrapping algorithms. The applied reconstruction techniques enable HDR recovery of color intensity and image details, ensuring better visual quality even under extreme lighting conditions at the cost of extra time. Experiments with the YOLOv10 model demonstrate that images processed using modulo images achieve performance comparable to HDR images and significantly surpass saturated images in terms of object detection accuracy. Moreover, the proposed modulo imaging step combined with HDR image reconstruction is shorter than the time required for conventional HDR image acquisition.
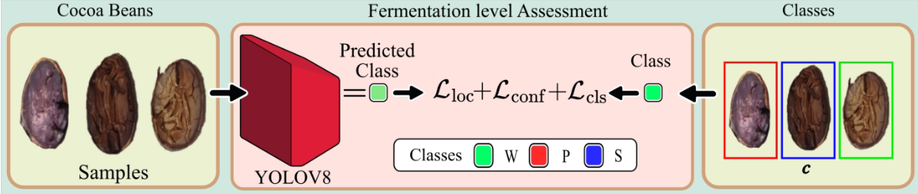
Automated Classification of Cocoa Bean Fermentation Levels Using Computer Vision
This study presents an automated system for classifying the fermentation levels of cocoa beans using convolutional neural networks, specifically employing YOLO-based object detection models. RGB images of cocoa beans, which were cut using a guillotine to expose their internal structure, were analyzed and manually labeled by experts according to the NTC 1252:2021 standard. A dataset of 19 high-resolution images, containing approximately 1,850 annotated beans, was used for both training and evaluation. Four versions of YOLOv8 (n, s, m, l) were tested, with YOLOv8m demonstrating the best overall performance, achieving an Intersection over Union (IoU) of 0.6522, accuracy of 0.6817, recall of 0.6558, and an F1-score of 0.6685. Comparative tests with earlier YOLO versions (YOLOv5 to YOLOv7) confirmed YOLOv8m as the most efficient model for this task. In addition, it achieved a competitive inference time of 89.87 ms per image. These results highlight the potential of deep learning and computer vision techniques to automate the classification of cocoa bean fermentation levels, providing a faster, more objective alternative to traditional manual inspection methods.
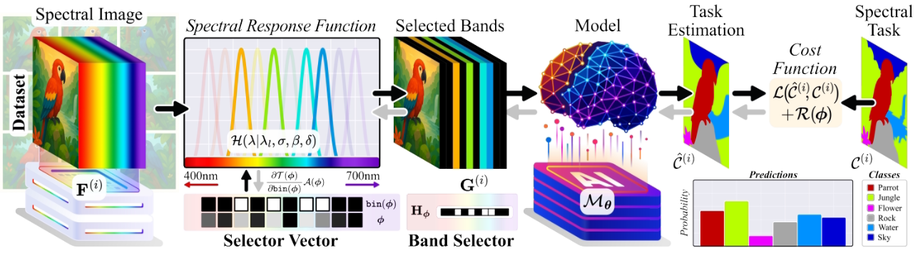
Deep Learning-Based Spectral Band Selection for Spectral Imaging Tasks
Spectral Images (SI) are acquired at multiple wavelengths across the electromagnetic spectrum, providing information that enhances performance in tasks such as material segmentation and classification by resolving ambiguities inherent in RGB images. SI devices are designed to capture a large number of spectral bands, which increases both cost and acquisition time, thereby limiting their practical deployment. However, not all spectral bands contribute equally to task-specific performance. To address this issue, a Deep Spectral Band Selection (DSBS) framework is proposed for spectral imaging tasks. Unlike previous methods that emphasize the preservation of non-task-specific information, DSBS identifies the most informative bands for a given task by jointly training a fully differentiable band selector and a neural network within an end-to-end learning framework. The selection process is guided by a proposed bin function and a custom lp-norm regularization term to achieve the desired number of spectral bands. Experimental results in material segmentation and classification tasks indicate that DSBS outperforms state-of-the-art machine and deep learning methods.
Learning-based Spectral Regression for Cocoa Bean Physicochemical Property Prediction
Predict physicochemical properties of cocoa beans from VIS-NIR spectral data using learning-based regression; dataset collected from Santander and evaluated across regions.
See the past: Time-Reversed Scene Reconstruction from Thermal Traces Using Visual Language Models
Time-reversed scene reconstruction from thermal traces using Visual-Language Models and constrained diffusion to recover past frames up to 120 seconds earlier.
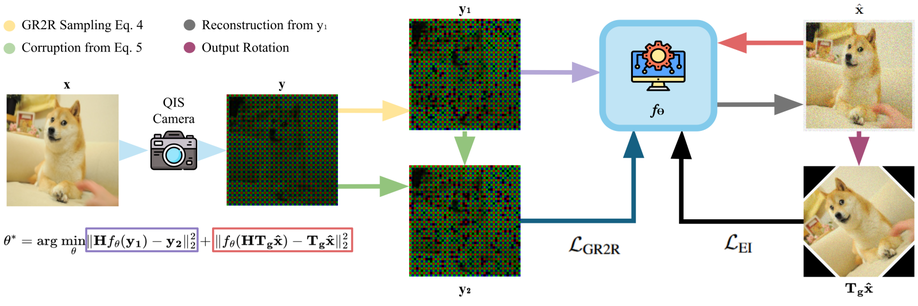
Self-Supervised Low-Light Quantum RGB Image Demosaicing
Image acquisition in low-light environments is fundamentally challenging due to the photon-limited nature of the scene, which results in severe noise and incomplete color information. Imaging sensors operating under such conditions require robust post-processing to recover visually coherent, full-color images. In these conditions, the photon arrival process can be modeled as a Poisson distribution, which introduces noise that complicates image reconstruction. Furthermore, the use of a color filter array leads to missing color information at each pixel, which exacerbates the challenge. As a result, denoising and demosaicing become ill-posed and interdependent tasks. We propose a self-supervised method that jointly addresses denoising and demosaicing under low-light conditions without requiring clean reference images. Our approach achieves a PSNR higher by 2.0 dB compared to best state-of-the-art methods at gain of 20 and is close to the supervised method.
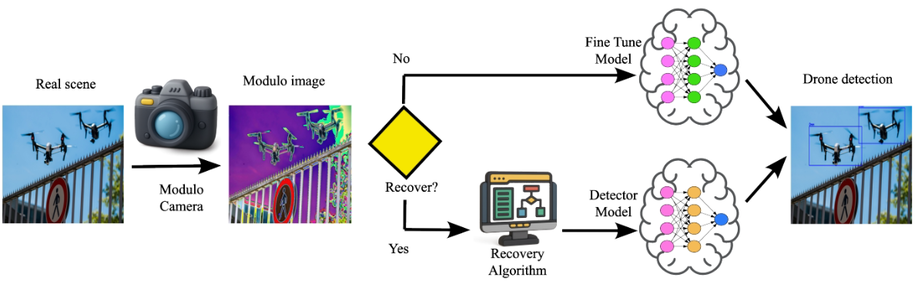
Deep Robust Object Detection Under High Illumination Conditions Using Modulo Images
Drone detection under high-illumination conditions remains a critical challenge due to sensor saturation, which degrades visual information and limits the performance of conventional detection models. A promising alternative to overcome this issue is modulo imaging, an approach based on modulo-ADCs that reset pixel intensities upon reaching a predefined saturation threshold, thus avoiding saturation loss. This work presents a methodology based on fine-tuning a detection model using modulo images, allowing accurate object detection without requiring High Dynamic Range (HDR) image reconstruction. Additionally, an optional reconstruction stage using the Autoregressive High-order Finite Difference (AHFD) algorithm is evaluated to recover high-fidelity HDR content. Experimental results show that the fine-tuned model achieves F1-scores above 96% across different illumination levels, outperforming saturated and raw modulo inputs, and approaching the performance of ideal HDR images. These findings demonstrate that fine-tuning with modulo data enables robust drone detection while reducing inference time, making the reconstruction process optional rather than essential.
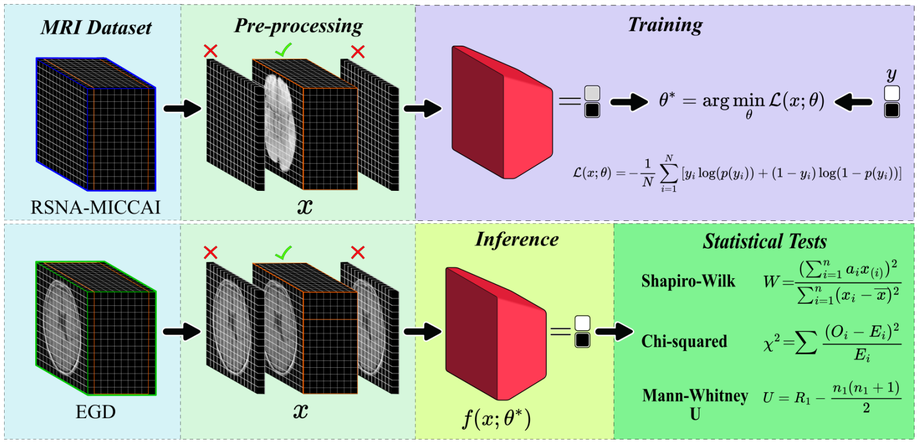
Deep Learning for Glioblastoma Multiforme Detection from MRI: A Statistical Analysis for Demographic Bias
Glioblastoma, IDH-wildtype (GBM), is the most aggressive and complex brain tumour classified by the World Health Organization (WHO), characterised by high mortality rates and diagnostic limitations inherent to invasive conventional procedures. Early detection is essential for improving patient outcomes, underscoring the need for non-invasive diagnostic tools. This study presents a convolutional neural network (CNN) specifically optimised for GBM detection from T1-weighted magnetic resonance imaging (MRI), with systematic evaluations of layer depth, activation functions, and hyperparameters. The model was trained on the RSNA-MICCAI data set and externally validated on the Erasmus Glioma Database (EGD), which includes gliomas of various grades and preserves cranial structures, unlike the skull-stripped RSNA-MICCAI images. This morphological discrepancy demonstrates the generalisation capacity of the model across anatomical and acquisition differences, achieving an F1-score of 0.88. Furthermore, statistical tests, such as Shapiro–Wilk, Mann–Whitney U, and Chi-square, confirmed the absence of demographic bias in model predictions, based on p-values, confidence intervals, and statistical power analyses supporting its demographic fairness. The proposed model achieved an area under the curve–receiver operating characteristic (AUC-ROC) of 0.63 on the RSNA-MICCAI test set, surpassing all prior results submitted to the BraTS 2021 challenge, and establishing a reliable and generalisable approach for non-invasive GBM detection.
A Review of Artificial Intelligence-Based Systems for Non-Invasive Glioblastoma Diagnosis
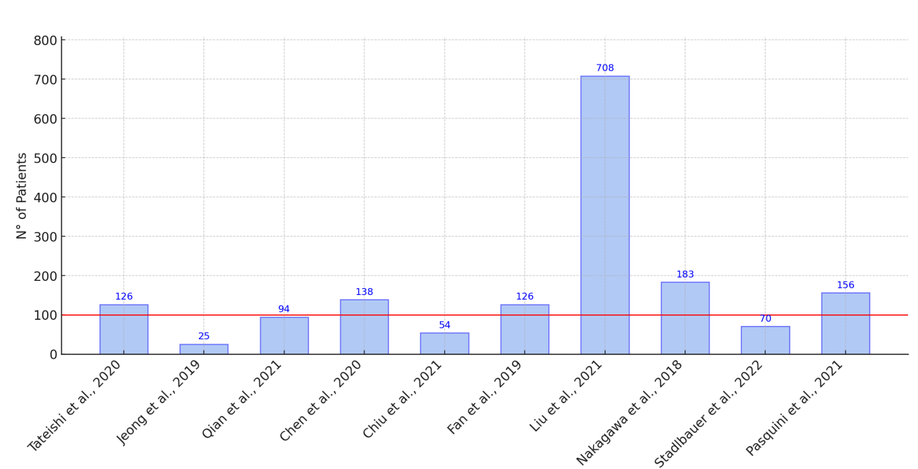
Glioblastoma multiforme (GBM) is an aggressive brain tumor with a poor prognosis. Traditional diagnosis relies on invasive biopsies, which pose surgical risks. Advances in artificial intelligence (AI) and machine learning (ML) have improved non-invasive GBM diagnosis using magnetic resonance imaging (MRI), offering potential advantages in accuracy and efficiency. Objective: This review aims to identify the methodologies and technologies employed in AI-based GBM diagnostics. It further evaluates the performance of AI models using standard metrics, highlighting both their strengths and limitations. Methodology: In accordance with the preferred reporting items for systematic reviews and meta-analyses (PRISMA) guidelines, a systematic review was conducted across major academic databases. A total of 104 articles were identified in the initial search, and 15 studies were selected for final analysis after applying inclusion and exclusion criteria. Outcomes: The included studies indicated that the signal T1-weighted imaging (T1WI) is the most frequently used MRI modality in AI-based GBM diagnostics. Multimodal approaches integrating T1WI with diffusion-weighted imaging (DWI) and apparent diffusion coefficient (ADC) have demonstrated improved classification performance. Additionally, AI models have shown potential in surpassing conventional diagnostic methods, enabling automated tumor classification and enhancing prognostic predictions.

Autoregressive High-Order Finite Difference Modulo Imaging: High-Dynamic Range for Computer Vision Applications
High dynamic range (HDR) imaging is vital for capturing the full range of light tones in scenes, essential for computer vision tasks such as autonomous driving. Standard commercial imaging systems face limitations in capacity for well depth, and quantization precision, hindering their HDR capabilities. Modulo imaging, based on unlimited sampling (US) theory, addresses these limitations by using a modulo analog-to-digital approach that resets signals upon saturation, enabling estimation of pixel resets through neighboring pixel intensities. Despite the effectiveness of (US) algorithms in one-dimensional signals, their optimization problem for two-dimensional signals remains unclear. This work formulates the US framework as an autoregressive l2 phase unwrapping problem, providing computationally efficient solutions in the discrete cosine domain jointly with a stride removal algorithm also based on spatial differences. By leveraging higher-order finite differences for two-dimensional images, our approach enhances HDR image reconstruction from modulo images, demonstrating its efficacy in improving object detection in autonomous driving scenes without retraining.